
단일행처리 함수
a. 문자처리 함수
length(value) : 글자수를 반환
instr(value, search, [position] , [occurrence]) : value에서 search의 인덱스를 반환
substr(value, position, [length]) : value에서 position부터 length개 잘라서 문자열 반환
lpad(value, len, [padding_str]) : len 에서 value의 길이를 뺀 만큼 padding_str를 왼쪽에 채워서 처리
rpad(value, len, [padding_str]) : len 에서 value의 길이를 뺀만큼 padding_str를 오른쪽에 채워서 처리
length(value) : 글자수를 반환
select
emp_name, length(emp_name), lengthb(emp_name),
email, length(email), lengthb(email)
from
employee;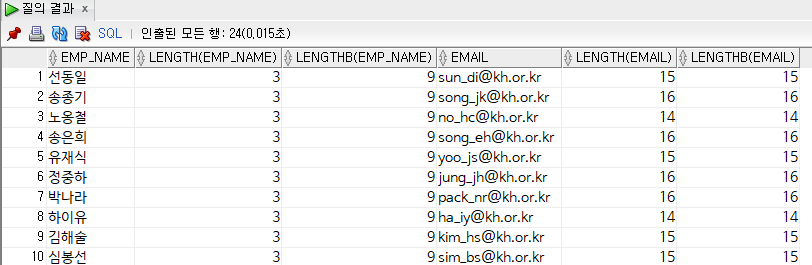
instr(value, search, [position] , [occurrence]) : value에서 search의 인덱스를 반환
position 검색 시작인덱스
occurrence 출현횟수
select
instr('kh정보교육원 국가정보원 정보문화사', '정보'), -- 3
instr('kh정보교육원 국가정보원 정보문화사', '정보', 1, 1), -- 3
instr('kh정보교육원 국가정보원 정보문화사', '정보', 1, 2), -- 11
instr('kh정보교육원 국가정보원 정보문화사', '정보', -1) -- 15
from
dual;
select
substr('show me the money', 6, 2), -- me
substr('show me the money', 6), -- me the money
substr('show me the money', -5)
from
dual;
select
emp_name,
substr(email, 1, instr(email, '@') - 1) id,
substr(email, 1, length(email) - length('@kh.or.kr')) id
from
employee;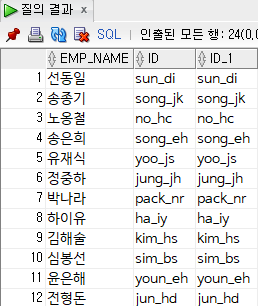
rpad(value, len, [padding_str]) : len 에서 value의 길이를 뺀만큼 padding_str를 오른쪽에 채워서 처리
select
lpad('123', 5, '0'),
lpad('12', 5, '0')
from
dual;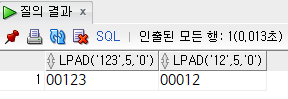
abs () : 절대값을 반환
mod () : 나머지를 반환
ceil : 소수점 기준 올림 (자릿수 옵션 없음)
round : 소수점 기준 반올림 (자릿수 옵션 있음)
floor : 소수점 기준 버림 (자릿수 옵션 없음)
trunc : 소수점 기준 버림 (자릿수 옵션 있음)
select
abs(10), abs(-10)
from
dual;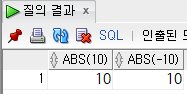
select
mod(10, 3)
from
dual;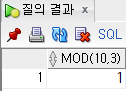
ex ) 생일 날짜가 짝수인 사원 조회
select
emp_name,
emp_no
from
employee
where
mod(substr(emp_no, 5, 2), 2) = 0; -- 주민번호 5,6번째 자리를 2로 나눈값이 0인 경우만 출력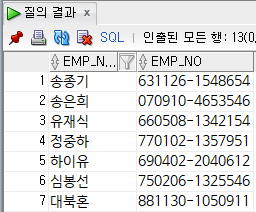
select
ceil(234.56 * 10) / 10,
round(234.56, 1),
floor(234.56 * 10) / 10,
trunc(234.56, 1)
from
dual;
c. 날짜처리함수
add_months (date, number) : 해당날짜에 지정한 개월수를 더하거나 뺀 날짜형을 반환. 말일에서 계산시 해당 달의 말일을 반환
extract (단위는 from date, timestamp) : 날짜정보 해당단위만 숫자형으로 반환. 시분초는 date가 아닌 timestamp타입에서만 추출가능
trunc(date) : 날짜형에서 시분초 정보를 제거
months_between(미래날짜, 과거날짜) : 두 날짜의 개월수 차이를 반환
add_months (date, number) : 해당날짜에 지정한 개월수를 더하거나 뺀 날짜형을 반환. 말일에서 계산시 해당 달의 말일을 반환
select
add_months(sysdate, 1),
add_months(sysdate, -1),
add_months('22/01/31', 1), -- 22/02/28
add_months('22/02/28', 1) -- 22/03/31
from
dual;
extract (단위는 from date, timestamp) : 날짜정보 해당단위만 숫자형으로 반환. 시분초는 date가 아닌 timestamp타입에서만 추출가능
select
extract(year from sysdate) yyyy,
extract(month from sysdate) mm, -- 1 ~ 12 숫자 반환
extract(day from sysdate) dd,
extract(hour from cast(sysdate as timestamp)) hh, -- timestamp로 형변환이 필요
extract(minute from cast(sysdate as timestamp)) mi,
extract(second from cast(sysdate as timestamp)) ss
from
dual;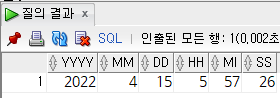
trunc(date) : 날짜형에서 시분초 정보를 제거
select
to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') "date",
to_char(trunc(sysdate), 'yyyy-mm-dd hh24:mi:ss') "date"
from
dual;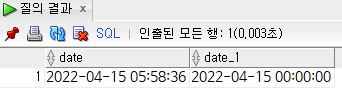
months_between(미래날짜, 과거날짜) : 두 날짜의 개월수 차이를 반환
select
round(months_between('23/01/01', sysdate), 1) "개월차"
from
dual;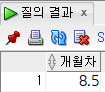
ex ) 사원테이블에서 사원의 근무 개월수 조회 (1. 근무개월수 n개월로 표시, 2. 근무개월수 x년 y개월로 표시)
select
emp_name,
hire_date,
trunc(months_between(sysdate, hire_date)) "근무개월수1",
trunc(months_between(sysdate, hire_date) / 12) || '년 ' ||
trunc(mod(months_between(sysdate, hire_date), 12)) || '개월' "근무개월수2"
from
employee;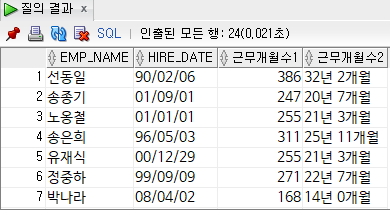
d. 형변환 함수
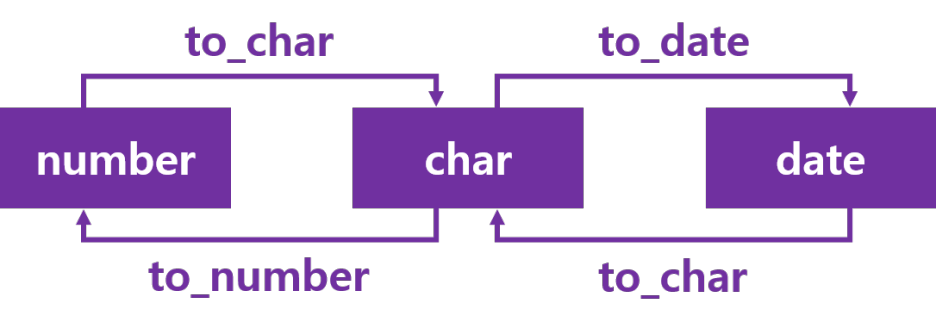
to_char
to_date
to_yminterval : 년과 월을 더해주는 함수 (n년 m개월)
to_dsinterval : 일 시간 분 초를 더해주는 함수 (n일 m시간 l분 p초)
to_char(date, format) : date를 지정한 format 형식으로 변환한 문자열 반환 (날짜형 -> 문자형)
day : 요일, dy : 짧은 요일 , d : 숫자 요일(일~토 1~7), am pm : 오전 오후
select
to_char(sysdate, 'yyyy/mm/dd (dy) am hh24:mi:ss') 짧은요일,
to_char(sysdate, 'yyyy/mm/dd (dy) am hh24:mi:ss', 'nls_date_language = korean') 요일을한국어로,
to_char(sysdate, 'yyyy"년" mm"월" dd"일"') yyyy년mm월dd일,
to_char(sysdate, 'fmyyyymmdd'), -- 포맷팅에 의해 생겨난 공백, 0등을 제거. 맨앞에 한번만 사용
to_char(sysdate, 'dy', 'nls_date_language=korean') 요일
from
dual;
to_char(number, format) : 충분한 자리수의 포맷을 사용 (숫자형 -> 문자형)
select
to_char(123456789, 'fm9,999,999,999'),
to_char(123.456, 'fm99999.99999'), -- 해당자리수가 없을때 소수점이상은 공백, 소수점이하는 0으로 처리. fm으로 제거가능
to_char(123.456, 'fm00000.00000'), -- 해당자리수가 없을때 소수점이상/이하는 모두 0으로 처리. fm으로 제거불가
to_char(123456789, 'FML9,999,999,999')
from
dual;
to_number(char, format) :
select
to_number('₩123,456,789', 'L999,999,999') + 1,
'1000' + 1
from
dual;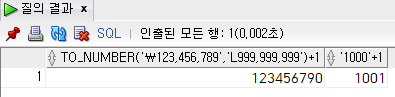
to_date(char, format) : 날짜데이터인 문자열을 지정된 형식에 맞게 날짜형을 변환 후 반환
select
to_date('1999/09/09', 'yyyy/mm/dd') + 1,
to_date('2022/04/14 (목) 19:08:33', 'yyyy/mm/dd (dy) hh24:mi:ss', 'nls_date_language = korean')
from
dual;
to_yminterval : 년과 월을 더해주는 함수 (n년 m개월)
ex ) to_yminterval('01-02')
to_dsinterval : 일 시간 분 초를 더해주는 함수 (n일 m시간 l분 p초)
ex ) to_dsinterval('01 02:03:04')
select
to_char(sysdate, 'yyyy/mm/dd hh24:mi:ss') now,
to_char(sysdate + 1 + (2 / 24) + (3 / 24 / 60) + (4 / 24 / 60 / 60), 'yyyy/mm/dd hh24:mi:ss') result,
to_char(sysdate + to_dsinterval('01 02:03:04'), 'yyyy/mm/dd hh24:mi:ss') result
from
dual;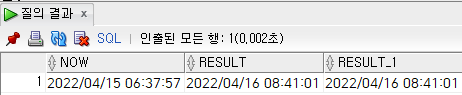
e. 기타함수
null 처리함수
nvl(value, null일때 값)
nvl2(value, notnull일때 값, null일때 값)
선택함수
decode(표현식, 값1, 결과값1, 값2, 결과값2, 값3, 결과값3, [기본값])
case
case 1)
case 표현식
when 값1 then 결과값1
when 값2 then 결과값2
......
[else 기본값]
end
case 2)
case
when 조건식1 then 결과값1
when 조건식2 then 결과값2
......
[else 기본값]
end
null 처리함수
nvl의 경우 지난 시간에 배웠다.
nvl2(value, notnull일때 값, null일때 값)
select
nvl2('abc', 'hello', 'world'),
nvl2(null, 'hello', 'world')
from
dual;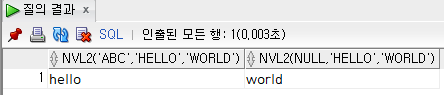
선택함수
decode(표현식, 값1, 결과값1, 값2, 결과값2, 값3, 결과값3, [기본값])
select
emp_name,
decode(job_code,
'J1', '대표',
'J2', '부사장',
'J3', '부장',
'J4', '차장',
'J5', '과장',
'J6', '대리',
'사원') job_name
from
employee;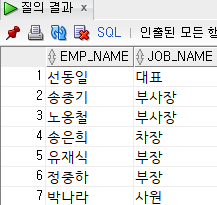
case
case 1)
case 표현식
when 값1 then 결과값1
when 값2 then 결과값2
......
[else 기본값]
end
select
emp_name,
case substr(emp_no, 8, 1)
when '1' then '남'
when '2' then '여'
when '3' then '남'
when '4' then '여'
end gender,
case substr(emp_no, 8, 1)
when '2' then '여'
when '4' then '여'
else '남'
end gender
from
employee;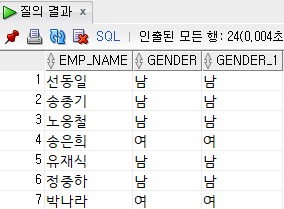
case 2)
case
when 조건식1 then 결과값1
when 조건식2 then 결과값2
......
[else 기본값]
end
select
emp_name,
case
when substr(emp_no, 8, 1) = '1' then '남'
when substr(emp_no, 8, 1) = '3' then '남'
when substr(emp_no, 8, 1) = '2' then '여'
when substr(emp_no, 8, 1) = '4' then '여'
end gender,
case
when substr(emp_no, 8, 1) in ('1', '3') then '남'
else '여'
end gender
from
employee;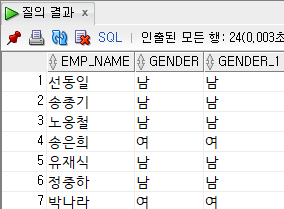
그룹함수
- 전체 행을 하나의 그룹으로 처리해서 그룹당 하나의 결과를 반환한다.
- group by 절을 통해 세부 그룹처리가 가능하다.
- 그룹함수의 결과와 일반컬럼을 동시에 사용할 수 없다.
- 컬럼값이 null인 경우는 연산처리하지 않는다.
sum(col) : 해당 col을 모두 더한 값을 리턴
avg(col) : 해당 col의 평균값을 리턴
count(col) : 컬럼값이 null이 아닌 컬럼수를 반환
max | min : 가장 큰,작은 수 / 사전등재가 가장늦은값 , 가장 빠른값 / 가장 미래, 가장 과거
sum(col) : 해당 col을 모두 더한 값을 리턴
select
sum(salary)
from
employee;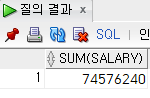
avg(col) : 해당 col의 평균값을 리턴
select
sum(salary),
trunc(avg(salary))
from
employee;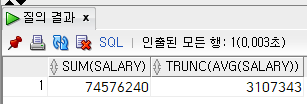
count(col) : 컬럼값이 null이 아닌 컬럼수를 반환
select
count(emp_id),
count(emp_name),
count(dept_code),
count(bonus),
count(*) -- 존재하는 행 카운팅
from
employee;

max | min : 가장 큰,작은 수 / 사전등재가 가장늦은값 , 가장 빠른값 / 가장 미래, 가장 과거
select
max(salary), min(salary),
max(emp_name), min(emp_name),
max(hire_date), min(hire_date)
from
employee;

마지막으로 오라클 랭귀지 레퍼런스
(오라클 내부함수 참고 링크)
https://docs.oracle.com/en/database/oracle/oracle-database/18/sqlrf/Format-Models.html