
금요일에는 DML에 대해 자세히 배워보았다.
초반에 테이블을 만들고 지우느라 Create, Delete기능을 사용하긴 했지만, 제대로 알진 않았기에 이번에 제대로 배워본다.
DML
Data Manipulation Language : 데이터 조작어
테이블 객체의 데이터에 대해 생성,조회, 수정, 삭제 (CRUD : Create , Read, Update, Delete) 하는 명령어
insert (Create)
select (Read)
update (Update)
delete (Delete)
dml명령어 수행시 메모리에서 우선작업하므로 TCL(Transaction Control Language)를 통해서 실제 db에 반영(commit), 작업취소(rollback)하는 과정이 필요하다.
* dml언어 사용시에만 commit, rollback 하면 된다.
INSERT
테이블에 새로운 레코드를 추가하는 명령어
명령 성공시마다 테이블에 행이 하나씩 추가
추가할 레코드에 컬럼값중에 하나라도 유효하지 않은 (자료형 불일치, 제약조건 불일치 등) 값이 있다면, 전체 레코드가 추가될 수 없다.
문법 1. 컬럼명 명시 x
테이블의 구조대로 값을 제공해야 한다. 컬럼순서, 컬럼 개수가 모두 일치해야 한다.
insert into
테이블명
values(컬럼값1, 컬럼값2, ...)
문법 2. 컬럼명 명시 o
컬럼 순서변경과 컬럼값 생략이 가능하고 레코드를 추가할 수 있다.
insert into
테이블명(컬럼1, 컬럼2, ...)
values(컬럼값1, 컬럼값2, ...)
create를 이용해서 table 만들기
create table study_ex(
a number,
b varchar2(20) default '안녕',
c varchar2(20) not null, --필수
d date default sysdate not null --필수
);not null 을 쓰면 필수 table이 된다.

내용이 비어있는 결과가 출력된다.
이제 insert로 값을 넣어보자.
문법 1을 사용할 것이다.
insert into
study_ex
values(
1,'hello','abcdefg',to_date('1999-09-09','yyyy-mm-dd')
);값이 순서대로 들어갔다.
insert into
study_ex
values(
1,'hello','abcdefg',to_date('1999-09-09'),10000
);--ORA-00913: too many values
value 10000이 한개 더 있어서 오류가 발생하고 값이 들어가지 않았다.
insert into
study_ex
values(
1,'hello','abcdefg'
);--ORA-00947: not enough values
value 1개가 부족해서 오류가 발생하고 값이 들어가지 않았다.
insert into
study_ex
values(null,default, null,default);--ORA-01400: cannot insert NULL into ("KH"."STUDY_EX"."C")
컬럼 C 는 not null 이라는 조건이 있기 때문에 null이 들어가면 오류가 발생한다.
insert into
study_ex
values(null,default, '가나다',default);값이 삽입되었다.
문법2도 사용해보자.
null컬럼만 생략이 가능하다.
not null컬럼도 default값이 지정되어 있는 경우 생략이 가능하다.
insert into
study_ex(c,d)
values('하이',to_date('2022-02-02','yyyy-mm-dd'));필수값이 c,d라 c,d만 지정해서 입력해도 행이 입력되었다.
insert into
study_ex(a,b)
values(2,'여보세요');--ORA-01400: cannot insert NULL into ("KH"."STUDY_EX"."C")
default값이 정해져 있지 않은 c를 입력하지 않아서 오류가 발생했다.
insert into
study_ex(a,b,c)
values(2,'여보세요','hello');필수값 c를 입력했더니 행이 입력되었다.
insert into
study_ex(a,b,c)
values(2,'안녕잘가안녕잘가안녕잘가','hello');--ORA-12899: value too large for column "KH"."SAMPLE"."B" (actual: 36, maximum: 20)
b의 최대길이는 20인데, 실제 길이는 36이라 오류가 발생했다.
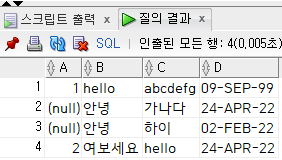
모든행을 출력해봤더니 다음과 같이 순서대로 입력되었다.
*연습용 employee_ee생성
create table employee_ee
as
select*
from
employee;select* from employee_ee;

employee 와 똑같은 테이블이 생성되었음을 알 수 있다.
desc employee_ee;

alter table employee_ee
add constraint pk_employee_ee primary key(emp_id) --기본키(식별자) 설정
add constraint uq_employee_ee_emp_no unique(emp_no) -- 유일키(중복허용X)
add constraint fk_employee_ee_dept_code foreign key(dept_code) references department(dept_id)--외래키
add constraint fk_employee_ee_job_code foreign key(job_code) references job(job_code) --외래키
--add constraint fk_employee_ex_manager_id foreign key(manager_id) references employee_ex(emp_id) --외래키
modify quit_yn default 'N' -- 기본값
modify hire_date default sysdate;alter table employee_ee
add constraint ck_employee_ex_quit_yn check(quit_yn in('Y','N'));--체크키이렇게 기본 설정을 마쳐준다.
현재 마지막 emp_id까지 내려보면

다음과 같이 나오게 되는데, 여기서 회원 3명을 insert로 추가해보자
insert into
employee_ee(emp_id,emp_name,emp_no,email,phone,dept_code,job_code,sal_level,salary,bonus,manager_id)
values('301','황지민','781020-2123453','hamham@kh.or.kr','01012343334','D1','J4','S3',4300000,0.2,'200');
insert into
employee_ee(emp_id,emp_name,emp_no,email, phone, dept_code, job_code, sal_level, salary, manager_id)
values ('302','장채현','901123-1080503','jang_ch@kh.or.kr','01033334444','D2','J7','S3',3500000,'201');
insert into
employee_ee(emp_id,emp_name,emp_no,job_code,sal_level)
values('303','신**','960313-2000000','J2','S1');
아래에 추가한 값이 뜨는 것을 알 수 있다.
Data Migration시에 유용한 insert구문
1. subquery를 사용한 insert구문
create table emp_info(
emp_id varchar2(3),
emp_name varchar2(50),
dept_title varchar2(50),
job_name varchar2(30)
);
insert into emp_info(
select
emp_id,
emp_name,
(select dept_title from department where dept_id = e.dept_code) dept_title,
(select job_name from job where job_code = e.job_code) job_name
from
employee e
);
24행이 삽입되었다고 뜬다.
2. insert all : 2개이상의 테이블에 나눠서 insert처리
employee
->emp_hire_date
->emp_manager
create table emp_hire_date(
emp_id varchar2(3),
emp_name varchar2(50),
hire_date date
);
where 1=0
create table emp_hire_date
as
select
emp_id, emp_name, hire_date
from
employee
where
1=0;where 1=0; 은 무조건false를 의미한다. 즉 레코드는 제외하고 테이블 구조(컬럼순서, 자료형)만 복제해서 만들겠다는 뜻이다.
create table emp_manager
as
select
emp_id,
emp_name,
manager_id,
emp_name"manager_name"
from
employee
where
1=0;alter table emp_manager
modify "manager_name" null;이제 두개의 테이블에 insert를 한번에 실행해보자.
insert all
into emp_hire_date values(emp_id,emp_name,hire_date)
into emp_manager values(emp_id,emp_name,manager_id, manager_name)
select
emp_id,
emp_name,
manager_id,
(selectd emp_name from employee where emp_id=e.manager_id) manager_name,
hire_date
from
employee e;다음과 같이 가능하다.
UPDATE(업데이트)
특정행을 찾아, 해당 컬럼값을 변경하는 명령
where절에서 특정행에 대한 조건을 제시 (where절 생략하면 모든 행에 대해 처리)
update
employee_ee
set
dept_code='D3',
job_code ='J3'
where
emp_id = '301';이후 커밋을 해주어야 한다. 그래야 sqlplus에서 바뀌게 된다.

실제로 sqlplus에서는 바뀌지 않았음을 알 수 있다.
하지만, 오라클에서 커밋을 하고나서 cmd창에서 다시 코드를 입력해보면

이제서야 값이 제대로 바뀌었음을 알 수 있다.
ex ) D5부서 직원의 급여를 100만원씩 인상

update
employee_ee
set
salary=salary+1000000
where
dept_code='D5';
월급이 100만원씩 오른 것을 확인할 수 있다.
*where절을 쓰지 않으면 모든 부서의 직원 월급이 오르므로 주의해야한다.
ex ) employee_ee테이블에서 임시환 사원의 직급을 과장, 부서를 해외영업 3부로 변경

원래 값은 회계관리부, 차장이다.
update
emp_info
set
dept_title='해외영업3부',
job_name='과장'
where
emp_name ='임시환';
commit;
업데이트 된 것을 알 수 있다.
update
employee_ee
set
dept_code=(select dept_id from department where dept_title='해외영업3부'),
job_code=(select job_code from job where job_name = '과장')
where
emp_name ='임시환';
commit;마찬가지로 employee_ee도 서브쿼리로 업데이트 해주었다.
DELETE
테이블의 행(레코드)를 삭제하는 명령
where절을 지정하지 않으면 모든 행이 삭제된다.(주의!)
실제 테이블 데이터의 삭제는 일어나지 않는다.
현재 employee_ee 는 27개의 행을 가지고 있다.

delete from
employee_ex
where
emp_id='303';
303번인 신**가 삭제된 것을 알 수 있다.
1. 소규모 데이터 - 삭제컬럼으로 처리됨.
update
employee_ee
set
quit_yn='Y',
quit_date=sysdate
where
emp_id='302';여기서 삭제 컬럼이 quit_yn인 것이다.
즉, 삭제컬럼이 'Y'인 경우, 보통의 사원조회때는 조회되어서는 안되는게 일반적이다.
select
*
from
employee_ee
where
quit_yn = 'N';quit_yn='N'을 기본값처럼 달고다녀야 한다. 그래야 실제 다니는 사원만 조회되기 때문이다.
2. 대규모데이터- delete처리. 삭제 데이터를 별도관리
삭제(delete)와 동시에 삭제 데이터를 퇴사자 테이블에 추가(insert)해서 관리
trigger객체를 통해 수월하게 처리 가능하다.
DML은 수행전 상태를 메모리상에 임시 보관한다. (before-image)
delete from
employee_ee;
다음과 같이 행이 다 사라졌으나 , 이상태에서 commit을 안했다면 rollback; 하면 다시 돌아온다.
truncate (전체 데이터 삭제)
DDL은 before-image작업 없이 즉시 실제 데이터베이스에 반영한다.
delete를 통한 전체 삭제에 비해서, 속도가 훨씬 빠르다.
truncate table employee_ee; 

아까와는 다르게 employee_ee가 잘렸습니다. 라고 나오고, rollback;을 해도 컬럼이 돌아오지 않는다.
진짜로 삭제된 것이다. (복구 불가)
오늘은 많이 들어봤던 기능 CRUD에 대해 제대로 배웠다.
Create , Read , Update , Delete 기능을 모두 잘 사용할 줄 알고 자유자재로 쓸 줄 알아야 진정한 DBMS의 고수가 아닐까 생각한다.
지금까지는 있는 데이터를 나타내는 방법만 배웠기 때문이다!
예제들을 풀어보면서 좀 더 어려운 것들을 해결해서 이해도를 높여봐야겠다.