JOIN
- inner join
- outer join 1. left outer join 2. right outer join 3. full outer join
- cross join
- self join
- multiple join
SET OPERATOR
- union
- union all
- intersect
- minus
이게 오늘까지 배운 내용의 요약이라 할 수 있다.
금요일에 배운 INNER JOIN, OUTER JOIN을 다시 보자.

INNER JOIN (이너 조인)
- 내부 조인. 두 테이블간의 교집합을 의미한다.
- 각 테이블에서 기준컬럼이 null인 행, 상대테이블에서 매칭되는 행이 없는 행 제외.
- inner 키워드 생략 가능. (inner) join으로 작성
예시
employee | department 테이블 내부 조인.
employee.dept_code = department.dept_id
INNER JOIN에서
employee테이블에서 dept_code가 null인 2행 제외됨.
department테이블에서 employee.dept_code에서 사용되지 않은 D3,D4,D7행 제외
select * from employee;

select * from department;

select
e.emp_name,
d.dept_title
from
employee e inner join department d
on e.dept_code = d.dept_id;이너조인 결과 (22행 출력)

OUTER JOIN (아우터 조인)
외부조인
좌/우측 테이블 기준으로 조인. 기준이 된 테이블은 누락되는 행이 없다.
outer키워드 생략 가능 . left (outer) join | right (outer) join
ex ) left outer join
employee 테이블 기준 모든 행을 포함한다.
24행 = 22행( inner join ) + 2행 (null값인 인턴)
select
emp_name,
dept_title
from
employee e left outer join department d
on e.dept_code = d.dept_id;
inner join 결과에 비해 하동운과 이오리가 추가된 것을 알 수 있다.
ex ) right outer join
department 테이블 기준 모든 행을 포함한다.
25행 = 22행 ( inner join ) + 3행 (사원이 없는 부서 D3, D4, D7)
select
d.dept_title,
e.emp_name
from
employee e right outer join department d
on e.dept_code = d.dept_id;
마케팅부, 국내영업부, 해외영업 3부가 null값을 가짐에도 출력된 것을 확인할 수 있다.
ex) full outer join
좌측과 우측이 모두 기준이 되어 좌 우측 테이블에서 제외되는 행이 없다.
27행 = 22행( inner join ) + 2행( 인턴 ) + 3행 ( 사원없는부서 D3,D4,D7 )
select
e.emp_name,
d.dept_title
from
employee e full outer join department d
on e.dept_code = d.dept_id;
27행이 출력된 것을 확인할 수 있다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------
금요일에 배운 내용은 여기까지다.
여기서 기준 컬럼명에 따라 유의할 점에 대해 알아보자.
기준 컬럼명이 다른 경우
ex ) employee e full outer join department d on e.dept_code=d.dept_id;
이 경우 별칭인 e와 d를 생략해도 정상처리된다. (하지만 사용하는 것을 추천)
기준 컬럼명이 같은 경우
별칭을 생략할 수 없다. 생략할 경우 오류 발생
natural join (네츄럴 조인)
컬럼명이 동일한 경우 모두 기준컬럼으로 사용하는 join.
using (컬럼명) 을 사용하고, 지정한 컬럼만 기준 컬럼으로 사용한다.
ex) employee 테이블의 job_code와 job테이블의 job_code를 사용해보자.
select *
from
employee e join job j
on e.job_code = j.job_code;
이 경우 inner와 full outer join이 같다. join 앞에 full을 붙여 실행해도 위와 같은 결과가 나오기 때문이다.
-> 내부/외부 조인처리결과가 같다
= employee 에 job_code가 null인 행이 없다는 뜻 & job 에 모든 job_code가 employee에 사용중이라는 뜻
cross join (크로스 조인)
상호조인. 모든 경우의 수대로 조인처리를 한다. 기준 조건절이 없다.
행을 Product 연산 한다고 보면 됨!
ex ) 직급별 평균 급여와 사원의 급여차이를 계산
1. 원래 직급별 평균 급여를 보기
select
job_code,
trunc(avg(salary)) avg_sal
from
employee
group by
job_code
order by
1;
2. 조인시 제외되는 행 찾기.
employee 테이블에 기준컬럼 job_code가 null인 사원을 찾으면 된다. (= employee에 매칭되는 행이 없는 행)
select
count(*)
from
employee
where
job_code is null;3. employee와 직급별 평균급여를 join
select
e.emp_name,
e.salary,
e.job_code,
j.avg_sal,
e.salary - j.avg_sal diff
from
employee e inner join (
select
job_code,
trunc(avg(salary)) avg_sal
from
employee
group by
job_code
order by
1
) j
on e.job_code = j.job_code;다중 셀렉트문이 가능. 크게보면 employee 와 직급별 평균급여를 join한 것이다.

결과는 다음과 같이 평균 급여와의 차이가 나오게 된다.
SELF JOIN (셀프 조인)
- 같은 테이블을 조인처리
- 테이블명과 컬럼명이 모두 동일하므로 테이블은 무조건 '별칭'을 붙인다.
ex) 사원명 / 관리자명 조회
select
e.emp_name,
m.emp_name manager_name
from
employee e left join employee m
on e.manager_id = m.emp_id;
MULTIPLE JOIN (멀티플 조인)
- 다중 조인. 여러 테이블을 동시에 조인처리
- ansi 표준문법에서는 조인되는 순서가 중요하다.
ex ) 직급이 대리/과장 이면서, ASIA 지역에 근무하는 사원을 부서명까지 조회.


사진 설명을 입력하세요.
select
*
from
employee e
join job j
on e.job_code = j.job_code
left join department d
on e.dept_code = d.dept_id
left join location l
on d.location_id = l.local_code
where
j.job_name in ('대리', '과장')
and
l.local_name like 'ASIA%';직급이 대리, 과장 -> job table의 job_code
지역이 ASIA -> location table의 local_name이 ASIA가 포함
부서명 -> department table의 dept_id
job_code 는 employee의 job_code와 조인, dept_id은 employee의 dept_code와 조인, location은 department의 location_id와 조인.
=
employee와 job테이블 먼저 조인하고, (같은 테이블 찾아서)
employee와 department테이블 조인하고
department와 location 테이블을 조인한다.
조인 순서가 굉장히 중요하며, 여러개를 조인하므로 공통 테이블을 잘 찾아야 한다.
NON-EQUI JOIN
조인 조건절에서 동등비교연산이 아닌 연산자를 사용해 조인하는 경우
ex) employee에서 salary(월급)가 min_sal보다 높거나 같고, max_sal보다 낮거나 같은 경우

sal_grade 코드는 다음과 같고, employee에도 sal_level이 존재한다.

select
*
from
employee e join sal_grade s
on e.salary between s.min_sal and s.max_sal;
결과는다음과 같이 나온다. salary 를 주목해보면 각 계급간 (S4의 경우 3000000~3999999) min_sal 과 max_sal 레벨 사이의 salary 값을 가지는 행만 출력된 것을 확인할 수 있다.
SET OPERATOR
집합연산자. 두개 이상의 결과집합을 세로로 연결해서 하나의 가상테이블(relation)을 생성한다.
조건
1. select절의 컬럼수가 동일해야함
2. select절에 상응하는 컬럼의 자료형이 일치해야함
3. order by절은 마지막 결과집합에서 단 한번 사용이 가능함
4. 컬럼명이 다른 경우, 첫번째 결과집합의 컬럼명을 사용함
종류
1. union 합집합 : 두 결과집합을 연결하되, 중복제거, 첫번째 컬럼기준 오름차순 정렬기능 지원
2. union all 합집합 : 두 결과집합을 그대로 연결. union보다 연산 속도가 빠름
3. intersect 교집합
4. minus 차집합
UNION / UNION ALL (합집합)
- (공통) 컬럼수, 컬럼 순서가 똑같아야함.
- 컬럼 수 불일치시 나타나는 오류 : ORA-01789: query block has incorrect number of result columns
- 자료형 불일치시 나타나는 오류 : ORA-01790: expression must have same datatype as corresponding expression
- (공통) union으로 연결된 것을 전자와 후자라고 할 때, 후자의 별칭을 바꿔주어도 적용되지 않는다. 다를 경우 첫번째 걸로 적용된다.
- (union만) 정렬을 하고싶다면 맨 마지막에만 orderby를 써주어야 한다.
-- 부서코드가 D5인 사원 조회 (사번, 사원명, 부서코드, 급여)
select
emp_id,emp_name,dept_code,salary
from employee
where
dept_code='D5'; --6행-- 급여가 300만원 이상인 사원을 조회(사번,사원명, 부서코드, 급여)
select
emp_id,emp_name,dept_code, salary
from employee
where salary>=3000000; --9행
--심봉선,대북혼 중복다음과 같은 코드가 있다고 치자.
union을 실시하면
select
emp_id 사원번호,emp_name,dept_code,salary-- 컬럼수, 컬럼 순서가 똑같아야함
from employee
where
dept_code='D5'
union
select
emp_id 사번 ,emp_name 사원명 ,dept_code 부서코드, salary 급여 --별칭 바꿔주어도 적용x. 첫번째걸로 적용됨
from employee
where salary>=3000000 --13행 , 중복2행 제거
order by salary desc; --맨마지막에만 써줘야함 orderby
중복인 대북혼과 심봉선이 빠지게 되어 13행이 출력된다.
하지만 union all을 사용하면
select
emp_id 사원번호,emp_name,dept_code,salary
from employee
where
dept_code='D5'
union all
select
emp_id 사번 ,emp_name 사원명 ,dept_code 부서코드, salary 급여
from employee
where salary>=3000000 ; --중복행 그냥 나옴. 제거되지 않음 
6,13행 4,12행에 심봉선과 대북혼이 중복됨을 알 수 있다.
INTERSECT(교집합)
- 중복된 행만 출력한다.
- 모든 컬럼값이 일치하는 경우에 출력한다.
- (공통) intersect로 연결된 것을 전자와 후자라고 할 때, 후자의 별칭을 바꿔주어도 적용되지 않는다. 다를 경우 첫번째 걸로 적용된다.
select
emp_id, emp_name, dept_code, salary
from
employee
where
dept_code = 'D5'
intersect
select
emp_id 사번, emp_name 사원명, dept_code 부서코드, salary 급여
from
employee
where
salary >= 3000000;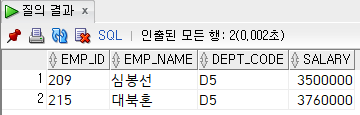
MINUS(차집합)
- 중복된 행만 빼고 전부 출력한다.
- minus 위에 쓴 집합에서 아래 결과집합과의 중복된 행을 제거하고 조회한다.
- 위 아래 쓰는 순서가 중요하다.
- (공통) minus로 연결된 것을 전자와 후자라고 할 때, 후자의 별칭을 바꿔주어도 적용되지 않는다. 다를 경우 첫번째 걸로 적용된다.
select
emp_id, emp_name, dept_code, salary
from
employee
where
dept_code = 'D5'
minus
select
emp_id 사번, emp_name 사원명, dept_code 부서코드, salary 급여
from
employee
where
salary >= 3000000;