DQL
Data Query Language : 테이블의 데이터를 검색(추출)하기 위해 사용하는 sql
DML의 하위 그룹으료 분류
데이터 조회결과를 Result Set(결과 집합)이라고 함.
조회시 0행 이상의 결과집합을 리턴받음.
select (필수) 5. 조회할 컬럼
from (필수) 1. 조회할 테이블
where 2. 조건절 (true - 결과집합에 포함, false - 결과집합에 제외)
group by 3. 행을 특정컬럼 기준으로 그룹핑
having 4. 그룹핑된 결과에 대한 조건절
order by 6. 행간 정렬
숫자는 실제 처리 순서이고, 이 순서대로 코드를 작성하는 것을 추천한다.
SELECT
- 실제 결과집합(result set)의 컬럼을 제한
- 존재하지 않는 컬럼도 조회함
- 가상컬럼 (연산처리결과) 사용 가능
- 123, '안녕' 같은 리터럴도 행수만큼 반복 출력
select
emp_name,
salary,
bonus,
nvl(bonus, 0),
salary * 12,
salary + (salary * nvl(bonus, 0)) as "실급여",
'안녕'
from
employee;
null 연산
- 이때 null과는 연산(산술연산, 비교연산) 할 수 없다.
- 결과값은 무조건 null이다.
-- nvl(nullableValue, nullValue) : null처리 함수
select
nvl('abc', 'xxx'),
nvl(null, 'xxx')
from
dual;
nullableValue를 null 로 할 경우 뒤의값 'xxx'로 나오게 된다.
위 실급여 계산을 수정해보자.
select
emp_name,
salary,
bonus,
nvl(bonus, 0),
salary * 12,
salary + (salary * nvl(bonus, 0)) as "실급여",
'안녕'
from
employee;
bonus가 null이어도 실급여가 제대로 나오는 것을 확인할 수 있다.
별칭붙이기
- result set의 컬럼명으로 사용
- as "별칭" : as, " " 생략이 가능
- 숫자로 시작하는 별칭, 공백 / 특수문자가 포함된 별칭은 " "로 반드시 감싸야 한다.
select
emp_name as "사원명",
emp_no "주민번호", -- as생략
phone 전화번호, --as, "" 생략
dept_code "직급 코드", --띄어쓰기 있어서 ""로감쌈
job_code "1_직급" --숫자로시작해서 ""로 감쌈
from
employee;
중복값 제거 distinct
- select구문 맨 앞에 한번만 사용 가능
- 여러 컬럼에 사용하면 여러 컬럼값을 합쳐서 중복을 판단함.
select distinct
dept_code
from
employee
order by
dept_code;
select distinct
dept_code, job_code
from
employee
order by
dept_code;
D1 J6 , D1 J7은 다른 값으로 판단 (행 기준 )
문자열 숫자연산자 ||
(숫자만 + 연산이 가능함. JAVA의 ||와 다름)
select
emp_name
from
employee;
select
'하잇! ' || emp_name || '님, ' || '안녕하세요'
from
employee;
앞뒤로 ||를 통해 붙일 수 있다는 것이 장점이다.
- +의 좌항과 우항을 무조건 숫자로 처리한다.
- 문자인 경우에도 자동으로 숫자로 형변환한다. 숫자가 아니라면 ORA-01722: invalid number 라는 오류 발생
select
1 + '123'
from
dual;
WHERE
- 지정한 테이블에서 행을 추려내기 위한 조건절
- 각 행마다 컬럼값을 검사해서 true가 반환된 행은 결과집합에 포함되고, false가 리턴된 행은 결과집합에서 제외된다.
|
연산자
|
설명
|
|
=
|
같다
|
|
!= <> ^=
|
같지않다
|
|
> >= < <=
|
크다,크거나같다,작다,작거나같다
|
|
between A and B
|
A이상 B이하에 포함여부
|
|
like | not like
|
문자열 패턴 비교
|
|
is null | is not null
|
null값 여부 비교
|
|
in | not in
|
비교값 목록에 포함 여부
|
|
and
|
좌항, 우항의 논리값이 모두 true인 경우 true 반환, 나머지 false 반환
|
|
or
|
좌항, 우항의 논리값이 하나라도 true인 경우 true 반환, 나머지 false 반환
|
|
not
|
반전
|
동등비교 (같다, 같지않다)
ex) 사원테이블에서 부서코드가 D6이면서 급여가 300만원보다 많은 사원 조회(사원명, 부서코드, 급여)
select
emp_name, dept_code, salary
from
employee
where
dept_code = 'D6'
and
salary > 3000000;
ex) 직급코드가 J1이 아닌 사원의 급여등급을 중복없이 출력
select distinct
sal_level
from
employee
where
job_code ^= 'J1'; -- != <> ^= 다 가능
ex) 부서코드가 지정되지 않은 사원을 조회 (사원명, 부서코드)
select
emp_name,
dept_code
from
employee
where
dept_code is null;
Between 연산자
Between A and B : A (작은값) 이상 B (큰값) 이하 범위에 포함되면 true를 반환
숫자형과 날짜형 처리 가능
ex) 급여가 350만원이상 600만원이하인 사원 조회(사원명, 급여)
select
emp_name,
salary
from
employee
where
salary between 3500000 and 6000000; -- salary >= 3500000 and salary <=60000000; 이랑 같음
ex) 급여가 350만원미만 또는 600만원 초과인 사원 조회(사원명, 급여)
select
emp_name,
salary
from
employee
where
not salary between 3500000 and 6000000; -- salary < 3500000 or salary > 6000000;와 같음
날짜범위도 연산해보자
ex ) 입사일이 90년 1월 1일 ~ 01년 1월 1일인 사원을 조회(사원명, 입사일)
select
emp_name, hire_date
from
employee
where
hire_date between '90/01/01' and '01/01/01';
형식은
yyyy/mm/dd
yy/mm/dd
yyyy-mm-dd
yymmdd 등 날짜포맷의 문자열을 사용하면 자동으로 날짜형으로 변환처리한다.
이때, 사용하면 혹시 ORA-01843: not a valid month 라는 오류가 발생하는 경우가 있다
도구 - 환경설정 - 데이터베이스 - NLS - 날짜언어와 기본언어가 같은지 확인한다
like , not like 문자열 패턴비교연산자
비교하는 값이 지정한 패턴을 만족하는 경우에 true를 반환한다.
% 를 사용할 경우 : 0개이상의 문자와 매칭 (개수 상관없음)
_ 를 사용할 경우 : 문자 1개와 매칭 (개수 중요)
ex) 전씨 사원 조회
select
emp_name
from
employee
where
emp_name like '전%';
select
emp_name
from
employee
where
emp_name like '전__';
두개의 결과가 같아서 무슨 차이인가 싶을 것이다. 데이터에는 모두 이름이 세글자인 사람만 있기 때문.
하지만, 실제로는 차이가 있다.
'전%' : '전' 이후에 0글자 이상이 연결된 경우. 전형돈(O), 전지연(O), 전(O), 전진(O), 전가라세(O)
'전__' : '전' 이후에 정확히 2글자가 연결된 경우. 전형돈(O), 전지연(O), 전(X), 전진(X), 전가라세(X)
이다.
_와 %는 위치를 자유롭게 지정할 수 있다. 응용을 해보자
ex ) 이름에 '이' 가 들어가는 사원을 모두 조회
select
emp_name
from
employee
where
emp_name like '%이%';
위치에 상관없이 '이'만 들어가면 모두 출력되었다.
ex ) 이메일의 '_' 앞글자가 3자리인 사원 조회.
escape 문자를 활용한다.
escape 문자는 자유롭게 지정할 수 있지만, 데이터에 포함되지 않은 문자여야 한다.
select
email
from
employee
where
email like '___\_%' escape '\'; 
in : 값 목록 포함여부 연산자
제시한 값목록에 포함되어 있으면 true 반환
null 값이 있는 컬럼은 in연산에도, not in 연산에도 포함되지 않는다.
ex ) 부서코드가 D6, D8 인 사원 조회
select
emp_name,
dept_code
from
employee
where
dept_code in ('D6', 'D8'); -- dept_code = 'D6' or dept_code = 'D8'; 이랑 같음
연산자 우선순위
1. 산술연산 | 연결연산
2. 비교연산
3. 논리연산 (not - and -or)
ex) 직급코드가 J2 또는 J7이고, 입사일이 90/01/01 ~ 01/12/31이고, 급여가 300만원 이상인 사원 조회
select
emp_name, job_code, hire_date, salary
from
employee
where
job_code in ('J2', 'J7')
and
hire_date between '90/01/01' and '01/12/31'
and
salary >= 3000000;
is null , is not null 비교
select
*
from
employee
where
dept_code is not null;
nvl을 이용하면 null 값 비교
select
*
from
employee
where
nvl(dept_code, '인턴') != '인턴';
ORDER BY
- 결과집합 처리시 마지막에 수행되는 절차로 추출된 행간의 순서를 다시 정렬하는 작업
- 컬럼기준 오름차순 asc (기본값) / 내림차순 desc
- 오름차순기준 : 문자형(사전 등재순), 숫자형 (작은수에서 큰수), 날짜형 (과거에서 미래)
select
emp_name 사원,
salary 급여,
hire_date 입사일
from
employee
order by
3 desc;
기준컬럼은 1개 이상 사용이 가능하다.
사원정보를 부서별 이름순으로 조회
null first, null last (null값에 대한 옵션 제공)
select
*
from
employee
order by
dept_code desc nulls last, emp_name asc;
FUNCTION
- 일련의 작업절차를 모아 놓은 database 객체
- 호출시에 인자를 전달하고, 리턴값을 받아 처리
- sql의 function은 반드시 리턴값을 가짐
함수유형
1. 단일행처리 함수 : 행마다 호출
a. 문자처리 함수
b. 숫자처리 함수
c. 날짜처리 함수
d. 형변환 함수
e. 기타 함수
2. 그룹처리 함수 : 그룹마다 호출
단일행처리 함수
a. 문자처리 함수
length(value) : 글자수를 반환
select
emp_name, length(emp_name), lengthb(emp_name),
email, length(email), lengthb(email)
from
employee;
instr(value, search, [position] , [occurrence]) : value에서 search의 인덱스를 반환
position 검색 시작인덱스
occurrence 출현횟수
select
instr('kh정보교육원 국가정보원 정보문화사', '정보'), -- 3
instr('kh정보교육원 국가정보원 정보문화사', '정보', 1, 1), -- 3
instr('kh정보교육원 국가정보원 정보문화사', '정보', 1, 2), -- 11
instr('kh정보교육원 국가정보원 정보문화사', '정보', -1) -- 15
from
dual;
substr(value, position, [length]) : value에서 position부터 length개 잘라서 문자열 반환
select
substr('show me the money', 6, 2), -- me
substr('show me the money', 6), -- me the money
substr('show me the money', -5)
from
dual;
ex ) 사원테이블에서 이메일 @ 앞의 아이디를 조회(사원명, 아이디)
select
emp_name,
substr(email, 1, instr(email, '@') - 1) id,
substr(email, 1, length(email) - length('@kh.or.kr')) id
from
employee;
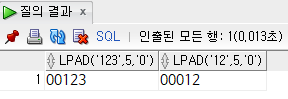
lpad(value, len, [padding_str]) : len 에서 value의 길이를 뺀 만큼 padding_str를 왼쪽에 채워서 처리
rpad(value, len, [padding_str]) : len 에서 value의 길이를 뺀만큼 padding_str를 오른쪽에 채워서 처리
select
lpad('123', 5, '0'),
lpad('12', 5, '0')
from
dual;